Docker---Prometheus监控

Docker—Prometheus监控

Prometheus需要多种第三方工具来收集数据,如接下来要使用的**cAdvisor和node-exporter**,最终Prometheus使用Grafana进行监控数据的展示
Prometheus是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社区也十分活跃,他们便将它独立成开源项目,并且有公司来运作。google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus 的优点
- 非常少的外部依赖,安装使用超简单
- 已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
- 服务自动化发现
- 直接集成到代码
- 设计思想是按照分布式、微服务架构来实现的
Prometheus 的特性
- 自定义多维度的数据模型
- 非常高效的存储 平均一个采样数据占 ~3.5 bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 强大的查询语句
- 轻松实现数据可视化
Prometheus的牛逼之处
为什么在市面上Prometheus比较火,下面看一下它到底牛逼在哪里
Prometheus是一个非常优秀的监控工具。准确的说,应该是监控方案。Prometheus提供了监控数据搜集,存储,处理,可视化和告警一套完整的解决方案
可以将它理解为图表显示器,或者资源整合器
下面是Prometheus的框架结构。如图。
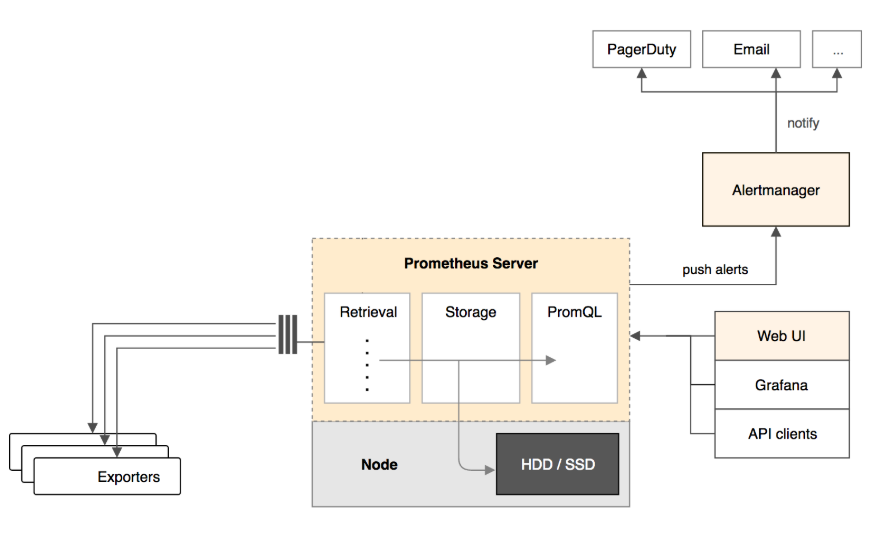
Prometheus Server
Prometheus Server负责从运行了node-exporter拉取和存储监控数据,并提供一套灵活的查询语言(promQL)供用户使用
node-exporter
exporter负责收集目标对象(host,container。。。)的性能数据,并通过HTTP接口供prometheus server获取
WebUI/Grafana/API clients
是一系列的可视化组件
监控数据的可视化展示对于监控方案至关重要。之前prometheus自己开发了一套工具,不过后来废弃了,因为开源社区出现了更优秀的产品:Grafana。Grafana能够与Prometheus无缝集成,提供完美的数据展示功能。
Alertmanager
用户可以定义基于数据监控的告警规则,规则会触发告警,会通过预定义的方式发出告警通知。支持的方式包括Email,pagerduty,webhook等
如果想要去了解Prometheus的详细原理,请参考官网
Prometheus的亮点
prometheus最大的亮点和先进性是他的多维数据模型
多维可以理解为,可以从不同的角度去让用户获取到用户想要看到的监控数据,比如同样是监控内存的使用情况,可以监控容器、镜像、user等使用内存的情况。下面会有例子
传统的数据模型指标
比如要监控一个容器时的内存时,进行定义一个指标名(memory_usage_web1),假如每分钟都进行一次内存使用的取样,就会形成如下图的记录

传统的数据指标是指,一个如上图所示的数据模型,只能记录一个web1的内存使用情况。如果现在需求发生了变化,要求监控所有web的内存使用情况,按照传统的数据模型的话,就需要增加很多新的类似上图的数据模型,也可以理解为在数据库中增加了启动web容器相同数量的表,一个记录web1,一个记录web2…..
像graphite这类更高级的监控方案采用了更为优雅的层次化数据模型,为了满足上面的需求,graphite会定义指标,将类似于web1、web2、web3等等的容器,进行下图所示的记录

可以用memory_usage_web*获取所有的web内存使用监控数据
此外graphite还支持sum()等函数对指标进行计算和处理,
比如:sum(memory_usage.web*)可以得到所有web容器占用的总内存量
目前为止,问题处理的都很好,但是客户也许会提出更多得需求:现在不仅按容器得名字统计内存使用量,还要按照镜像来统计;或者想对比一下某一组容器在生产环境和测试环境中内存使用的不同情况
如果按照传统得方案:只要定义更多得指标就能满足这些需求,比如:
memory_usage_image1_app1,memory_usage_app1_prod等
但问题在于我们没办法提前预知客户要用这些数据回答怎样得问题,所以没办法提前定义好所有得指标
Prometheus满足用户的解决方案
promethues只需要定义一个全局得指标memory_usage,然后通过添加不同得维度数据来满足不同得业务需求
比如对于前面的web的取样数据,转换成prometheus多维数据变成

可以看到在后面追加了容器(container)、镜像(image)、使用环境(env),这就是三个维度的内存使用信息
test:测试环境 prod:生产环境
如果不同的环境,不同的image他们的内存使用数据中标注了三个维度,就能够去满足很多的业务需求
比如:
可以计算某个web1容器的平均内存使用情况,使用avg()函数:
avg(memory_usage{container_name=’web1’})
计算使用多个容器使用centos镜像,所使用的内存数据:
sum(memory_usage{image=’centos:7’})
计算不同环境中容器的使用量
sum(memory_usage{container=~’web’})by (env)
Prometheus的优势
1.通过维度对数据进行说明,附加更多的业务信息,进而满足不同业务的需求。同时维度是可以动态添加的,比如再给数据添加一个user维度,就可以按照用户来统计内存的使用量了。
2.prometheus丰富的查询语句能够灵活,充分挖掘数据的价值。比如对数据进行计算,这些只是查询语言中很小的一部分功能。Prometheus 对多维数据进行分片、聚合的强大能力。
监控环境
在接下来的使用中会进行监控两个主机的容器以及主机数据
| ip | 服务 | 备注 |
|---|---|---|
| 192.168.1.11 | docker(已安装) | |
| 192.168.1.12 | docker(已安装) |
cAdvisor数据收集
Prometheus监控将cAdvisor监控作为一个监控容器数据收集器
cAdvisor是google开发的容器监控工具
cAdvisor操作界面简陋,需要在不同的页面之间跳转,并且只能监控一个主机,但是它的亮点是,它可以将监控到的数据导出给第三方工具,比如接下来要做的Prometheus。
cAdvisor的主要功能
- 展示主机和容器两个层次的监控数据
- 展示历史变化数据
在与Prometheus搭配使用时,可以将cAdvisor定位为一个监控数据收集器,收集和导出数据是它的强项,而非展示数据。
CAdvisor的下载
两台主机都进行下载
镜像名为google/cadvisor
[root@localhost ~]# docker pull google/cadvisor下载完成
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 83aa35aa1c79 4 weeks ago 1.22MB
httpd latest c5a012f9cf45 5 weeks ago 165MB
centos latest 5e35e350aded 4 months ago 203MB
google/cadvisor latest eb1210707573 17 months ago 69.6MBcAdvisor的运行
[root@localhost ~]# docker run --volume /:/rootfs:ro --volume /var/run:/var/run:ro \
--volume /sys:/sys:ro --volume /var/lib/docker:/var/lib/docker:ro \
--publish 8080:8080 --detach=true --name cadvisor google/cadvisor
# 参数解释
--publish=-p:端口映射
--detach=true=-d:后台运行
5d9de1920f8a15f4efbb479dbcc1b835a1b2332e34bc91155a8058a424fa147a防火墙放行端口8080
[root@localhost ~]# firewall-cmd --add-port=8080/tcp访问网址http://192.168.1.11:8080,如图
使用cAdvisor监控容器
192.168.1.11
运行三台web,三台centos
[root@localhost ~]# docker run -itd --name web1 httpd
34d1d4c795dd58dffa449120a1f41c562f612fa9393cc8844f170c386448c715
[root@localhost ~]# docker run -itd --name web2 httpd
0a5ea42b1c75e5831f6df618e6388b0cc0e5e4fd73e8e7ec831df6aeb3be0088
[root@localhost ~]# docker run -itd --name web3 httpd
8053ea050473049ecbdd10a140acac7ecfda15aedfc2b3ba6ef4e5d8c518dd70
[root@localhost ~]# docker run -itd --name sys1 centos
0f347ceaa4b15d80b4361d7a409d09556872a14c4b865052fbf3a6b866b32aee
[root@localhost ~]# docker run -itd --name sys2 centos
abab8db4e2f0825fe2d0e468d5ab56b921984582f0c3c309805831329c26846a
[root@localhost ~]# docker run -itd --name sys3 centos
1c7baf50f5c879acad9bd5e6b618aea900abf7f7dcf997afeadcd3314275cf72点击页面中的Docker Containers就可以看到运行的几个容器,也可以点击进入容器
cAdvisor可以展示主机和容器的硬件资源使用率
由于只是使用cAdvisor进行数据的收集,不去多进行cAdvisor页面中的操作
验证结束之后先将这个容器停掉,以免去影响后续Prometheus的操作
[root@localhost ~]# docker rm -f cadvisorPrometheus监控
node-exporter:负责采集主机的信息和操作系统的信息,以容器的方式运行在监控主机上
cAdvisor:负责采集容器的信息,以容器的方式运行在监控主机上
所以以上两个镜像是在要监控的docker主机上进行下载运行的。
Prometheus的下载
192.168.1.11
只需要在一台中进行下载Prometheus的镜像即可,作为Prometheus服务器
node-exporter主要用来收集主机的硬件使用数据,这样就可以使用cAdvisor和node-exporter将容器与主机的数据都进行了收集
[root@localhost ~]# docker pull prom/prometheus
[root@localhost ~]# docker pull prom/node-exporter192.168.1.12
需要下载node-exporter,在前面已经下载过cAdvisor,同样也是为了收集这台主机的容器以及硬件的使用数据。
[root@localhost ~]# docker pull prom/node-exporter运行exporter
192.168.1.11
以下映射的目录大部分都在/var/lib/docker目录下
exporter的端口号为9100 ,因为使用了网络驱动类型为host,所以会自动使用宿主机的9100端口
[root@localhost ~]# docker run -d --volume /proc/:/host/proc \
--volume /sys/:/host/sys --volume /:/rootfs --network host --name exporter \
prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points \
"^(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers\
|rootfs/var/lib/docker/overlay2\
|rootfs/run/docker/netns|rootfs/var/lib/docker/devicemapper\
|rootfs/var/lib/docker/aufs)($$|/)"
61e196748f0e8caae22be04966327a56d2f3783e3f5caeea2b4dcb960416a2a1放行防火墙端口
[root@localhost ~]# firewall-cmd --add-port=9100/tcp
success建议使用
netstat -anput | grep 9100,检查端口是否启动,没有启动则检查容器运行错误
访问http://192.168.1.11:9100/metrics,能出现以下内容即成功
192.168.1.12
和1.11相同的操作
[root@localhost ~]# docker run -d --volume /proc/:/host/proc \
--volume /sys/:/host/sys --volume /:/rootfs --network host --name exporter \
prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points \
"^(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers\
|rootfs/var/lib/docker/overlay2\
|rootfs/run/docker/netns|rootfs/var/lib/docker/devicemapper\
|rootfs/var/lib/docker/aufs)($$|/)"
5c172fee94abd71e459a19ef291336ff1be2564e97493f262219163cddef78fd放行防火墙端口
[root@localhost ~]# firewall-cmd --add-port=9100/tcp
success建议使用
netstat -anput | grep 9100,检查端口是否启动,没有启动则检查容器运行错误
验证访问http://192.168.1.12:9100/metrics
运行cAdvisor
之前的cAdvisor已经删除了,来重新运行cAdvisor来监控容器状态
cAdvisor的端口号是8080,也会使用host的网络驱动,与主机共用网络,所以不需要去映射端口
192.168.1.11
[root@localhost ~]# docker run --volume /:/rootfs:ro --volume /var/run:/var/run:rw \
--volume /sys:/sys:ro --volume /var/lib/docker:/var/lib/docker:ro \
--network host -d --name cadvisor google/cadvisor
65a5f0322a1fe99b68bd4f96487a268fd3b7dfd8eee85070f0582d2954515f42放行防火墙端口号
[root@localhost ~]# firewall-cmd --add-port=8080/tcp
success建议使用
netstat -anput | grep 8080,检查端口是否启动,没有启动则检查容器运行错误
访问http://192.168.1.11:8080/metrics,页面出现以下内容

192.168.1.12
[root@localhost ~]# docker run --volume /:/rootfs:ro --volume /var/run:/var/run:rw \
--volume /sys:/sys:ro --volume /var/lib/docker:/var/lib/docker:ro \
--network host -d --name cadvisor google/cadvisor
6a624e53e2fa698b904776dc56446eebee853b06509305184ddb01bf2263443c放行防火墙端口号
[root@localhost ~]# firewall-cmd --add-port=8080/tcp
success建议使用
netstat -anput | grep 8080,检查端口是否启动,没有启动则检查容器运行错误
验证访问http://192.168.1.12:8080/metrics
配置Prometheus Server
192.168.1.11
需要使用一个yml文件来指定需要监控的内容,将两台主机的cAdvisor与exporter监控到的数据拉取到Prometheus Server中
将这个配置文件映射到Prometheus Server的容器中
去官网找示例文件,修改为如下,我这里是使用的官网的最下面的那个示例,截止到startic_configs:
修改内容:rule_files注释掉,添加static_configs:下面的内容,用来指定exporter抓取的数据
[root@localhost ~]# vim prometheus.yml
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # Evaluate rules every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
rule_files:
# - 'prometheus.rules.yml'
scrape_configs:
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
# scrape_interval: 5s
static_configs:
- targets: ['192.168.1.11:9090','192.168.1.11:8080','192.168.1.11:9100','192.168.1.12:8080','192.168.1.12:9100']在以上文件中,将两台主机的5个ip:port都添加即可,9090为Prometheus Server的端口
运行Prometheus Server容器
这里也是因为使用主机网络的原因不去映射端口,9090为Prometheus的访问端口
[root@localhost ~]# docker run -d --network host \
--volume /root/prometheus.yml:/etc/prometheus/prometheus.yml \
--name prometheus prom/prometheus
27176618fc718181e8f47b95ce5968bc882a65e50e4cd6e755dce49256aed8fd防火墙放行端口
[root@localhost ~]# firewall-cmd --add-port=9090/tcp
success建议使用
netstat -anput | grep 9090,检查端口是否启动,没有启动则检查容器运行错误
访问192.168.1.11:9090
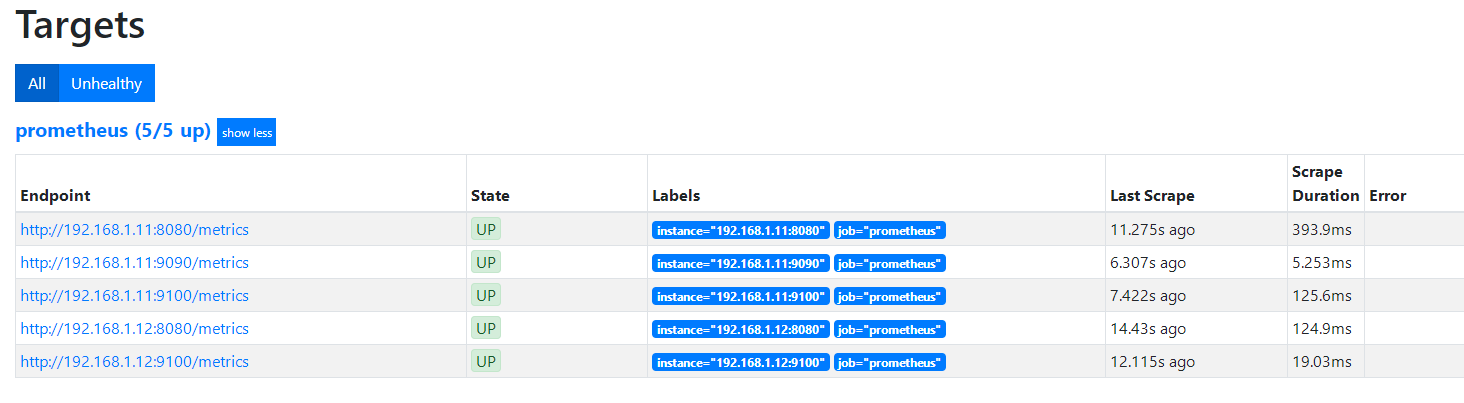
点击状态中的targets,查看运行主机
全部为up即可,如果有的是down,则检查显示down的对应主机的端口号
grafana可视化
监控搭建完毕,最后使用grafana可以显示更加绚丽的图形化界面
grafana的下载
只需要在Prometheus Server所运行的主机下载即可
[root@localhost ~]# docker pull grafana/grafanagrafana的运行
grafana的端口号是3000,同样使用host类型的网络驱动,来进行映射,默认使用物理机的3000端口
[root@localhost ~]# docker run -d -i --name grafana --network host \
-e "GF_SERVER_ROOT_URL=http://grafana.server.name" \
-e "GF_SECURITY_ADMIN_PASSWORD=secret" grafana/grafana
5bf635e732393af62b72f46be13c491f4b6cc625e030ca7318825867be280877防火墙放行端口
[root@localhost ~]# firewall-cmd --add-port=3000/tcp
success建议使用
netstat -anput | grep 3000,检查端口是否启动,没有启动则检查容器运行错误
访问http://192.168.1.11:3000
grafana对浏览器有要求,如果配置没有报红色的错误,而是如下图的绿色的login in,就是浏览器的问题了

我这里使用搜狗和谷歌都不行,windows自带的edge更是弱到爆炸,虚拟机的firefox版本低,最后只能在自己的电脑上下载了firefox才成功访问,
这里的用户名admin是默认的,密码在启动时通过变量指定为secret

图形化界面的操作
点击首页中的Add data source,添加数据源
选择**Prometheus**
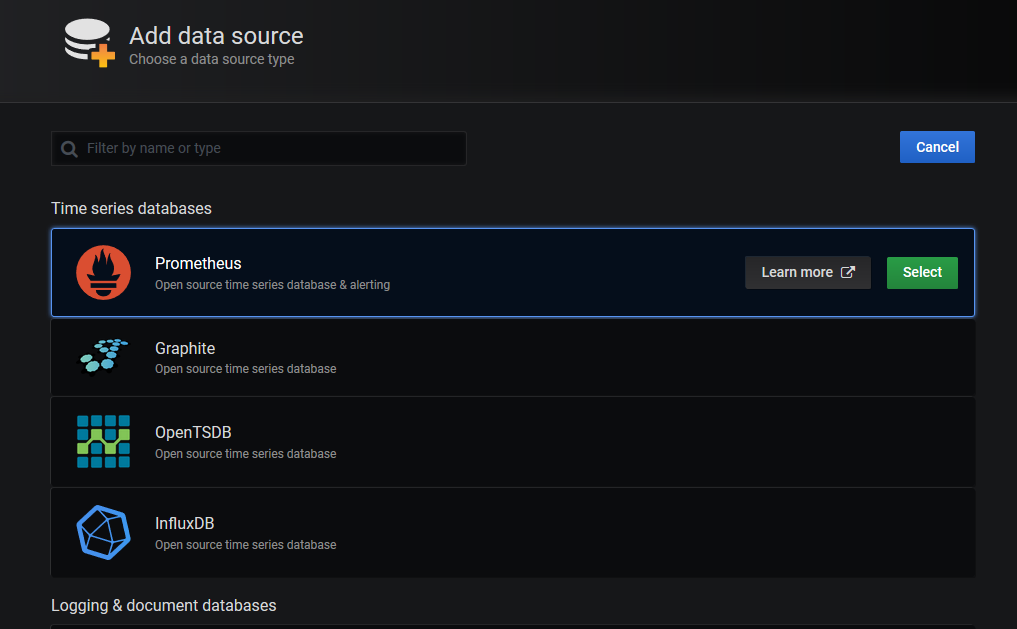
这里只需要填写Prometheus Server的URL路径即可
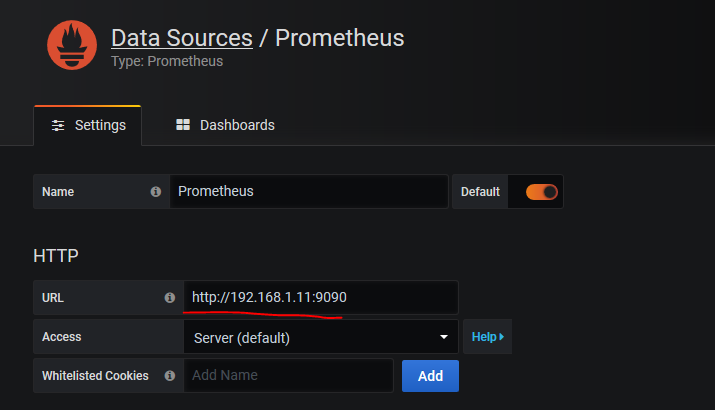
点击下方**Save & Test**保存
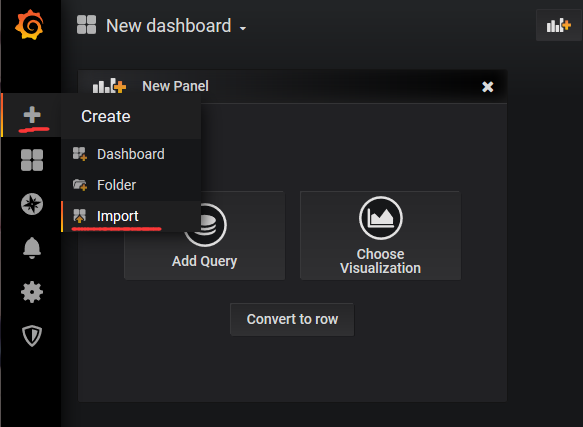
成功之后返回首页,添加仪表盘(dashboard),这里使用导入文件的方式
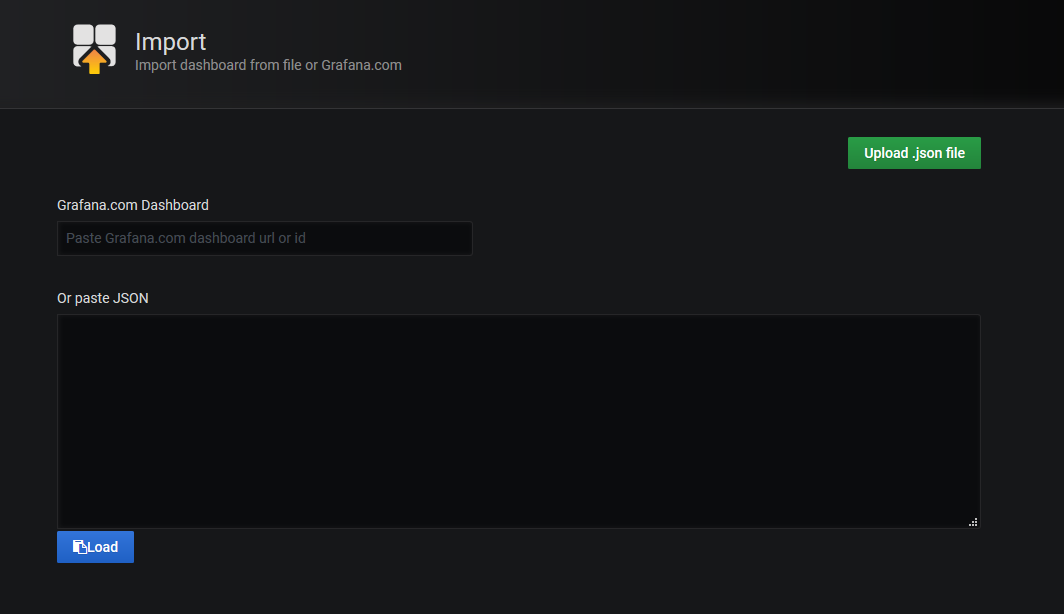
上图中的空白处需要添加一个json文件,需要从grafana的官网进行下载,这里可以选择关于Docker的仪表盘,很多种类,这里以官方使用的为主,点击这里使用接下里要用的dashboard,进入页面后,如图所示,根据图中红线处即可下载
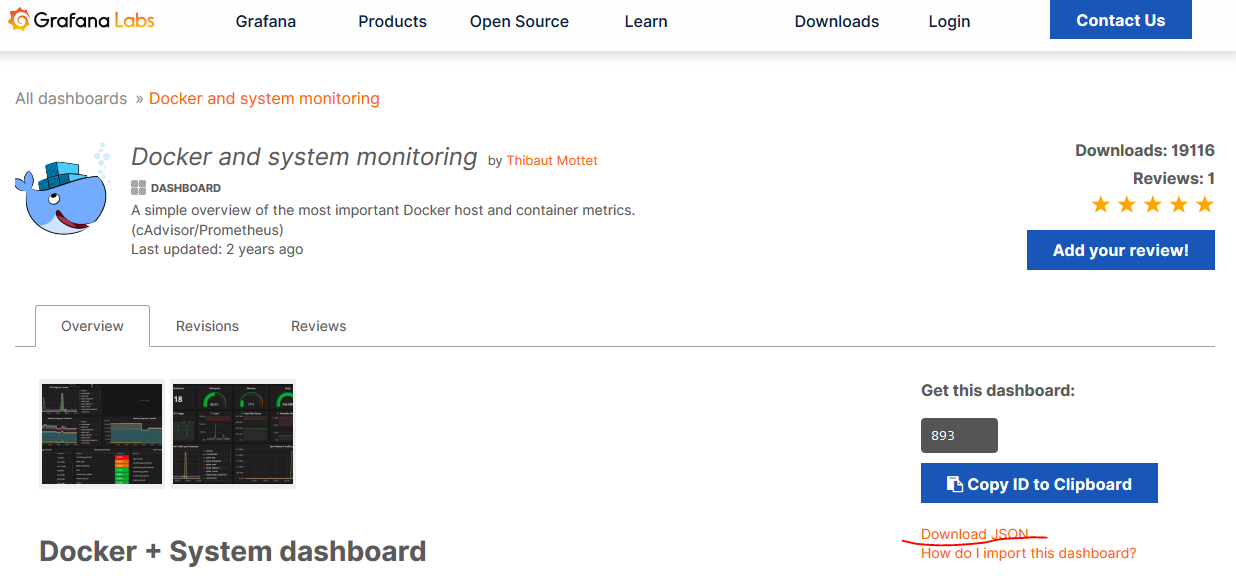
下载完成后,回到本地的grafana界面,进行文件的上传,找到自己的下载位置上传即可
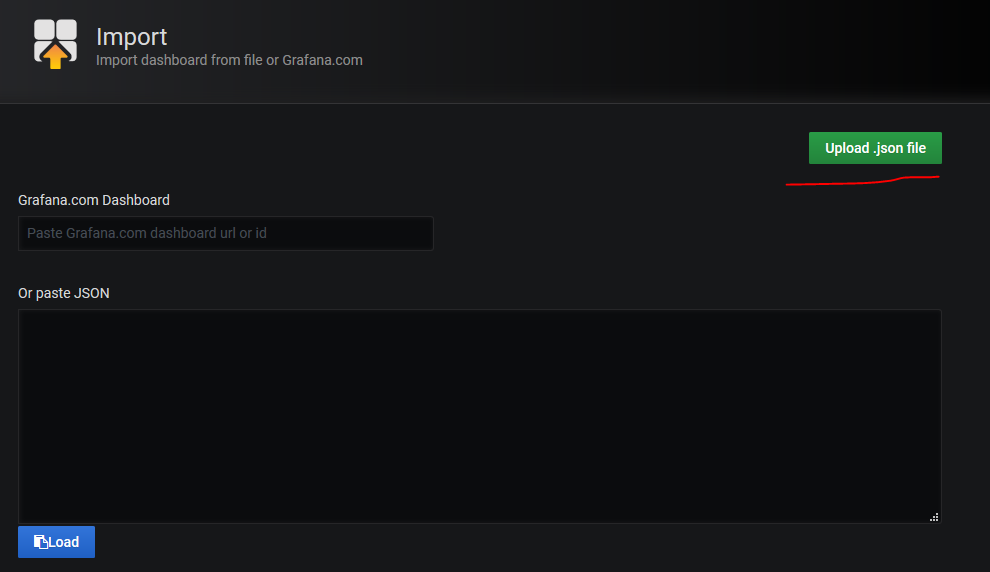
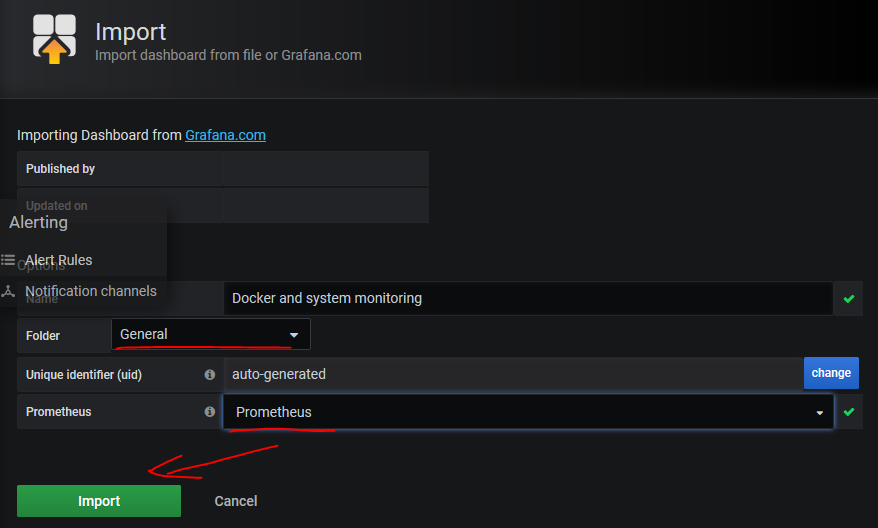
成功之后,如图所示
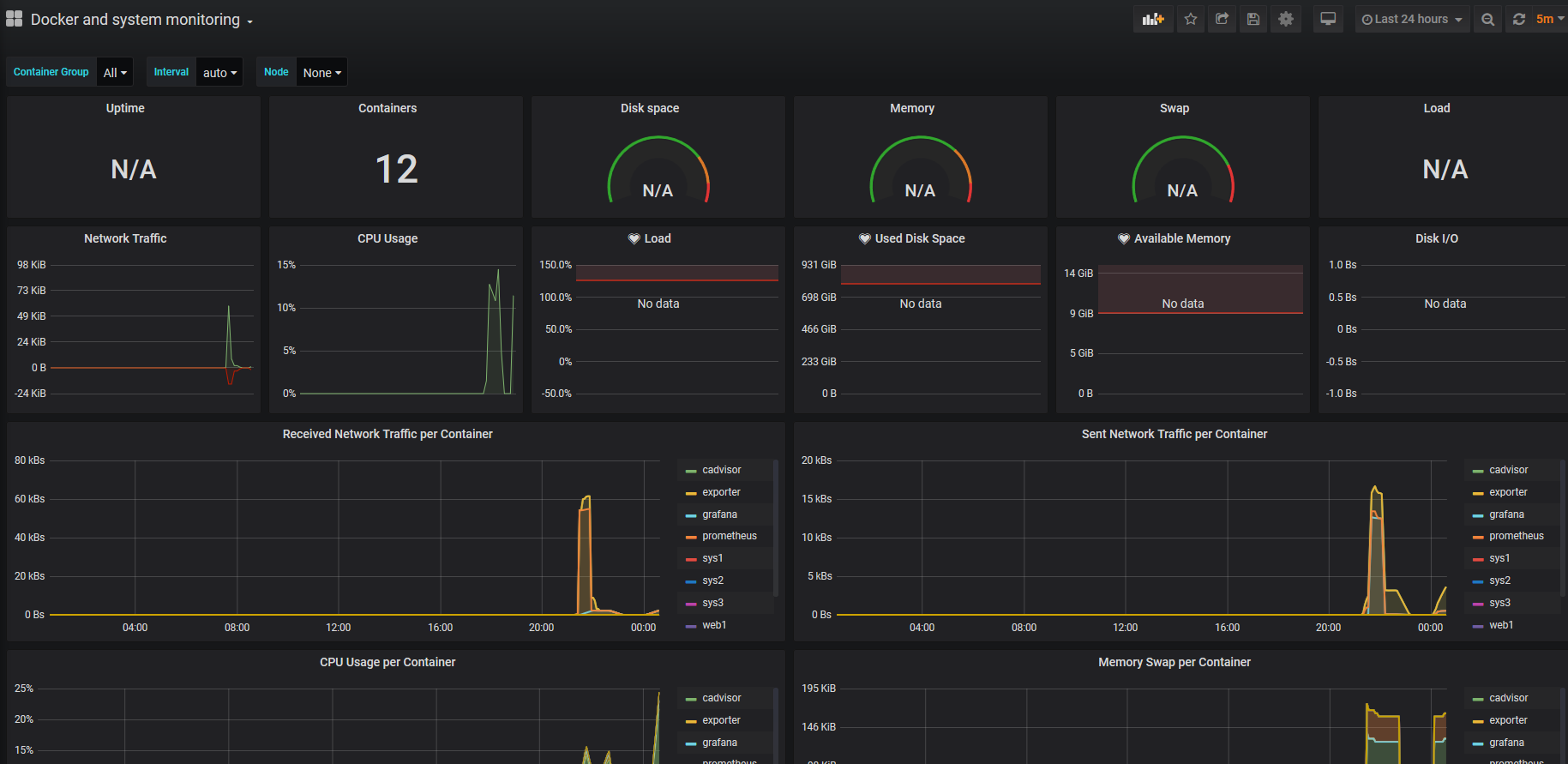
其中可以看到disk硬盘使用,mem内存使用,cpu只要用,swap交换空间使用,也可以看到关于容器的内存使用、网络使用
其他的操作,自己日后可以去研究点点看,很灵活的一款监控方案
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://www.feiyiblog.com/2020/04/08/Docker-Prometheus%E7%9B%91%E6%8E%A7/


