ELK日志分析系统

![]()
ELK日志分析系统
本文参考链接: https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html
概念
awk、grep、cat、tail等命令可以对日志进行简单筛选,面对海量日志的场景,简单操作,效率过低
ELK是elastic公司提供的一套完整的日志收集以及展示的解决方案,三个产品首字母缩写是ELK,分别是ElasticSearch、Logstash和Kibana
ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,使用Java语言编写。
Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集、解析、并将数据发送给ES
Kibana为ElasticSearch提供了分析和可视化的Web平台。可以在ElasticSearch的索引中查找,交互数据,并生成各种维度表格,图形
用途
传统意义上,ELK作为替代Splunk的一个开源解决方案。Splunk是日志分析领域的领导者。日志分析不仅仅包括系统产生的错误日志、异常,也包括业务逻辑,或者任何文本类的分析。而基于日志的分析,能够在其上产生非常多的解决方案,比如:
- 问题排查,日志分析技术是问题排查的基石。基于日志做问题排查。
- 监控和预警,日志、监控、预警是相辅相成的。基于日志的监控、预警使得运维有自己的机械战队,大大节省人力以及延长运维的寿命。
- 关联事件,多个数据源产生的日志进行联动分析,通过某种分析算法,就能解决各个问题。
- 数据分析
ELK角色
1、采集端:agent,对日志的源数据进行采集进行封装,发送到聚合端
2、聚合端:collector,接收来自采集端的数据,按照规则进数据处理,将数据发送给存储端
3、存储端:storage,也就是elasticsearch,负责数据存储(可扩展性、可靠性),和索引
常见的方案
ELF、EFK、graylog、ELK流式分析
部署Kafka+ELK+Beats环境
实验环境
推荐单台主机使用3G内存或者2G,优先3G
| 主机 | 服务 | 备注 |
|---|---|---|
| 192.168.1.1 | ElasticSearch | 内存3G |
| 192.168.1.4 | Kibana/Kafka/Zookeeper | 内存3G |
| 192.168.1.5 | Logstash | 内存3G |
| 192.168.1.6 | FileBeat/Nginx | 内存3G |
实验步骤
192.168.1.1需要jdk(java)/ElasticSearch
配置java环境
tar zxf jdk-8u201-linux-x64.tar.gz
mv jdk1.8.0_201/ /usr/local/java
vim /etc/profile
# 末尾添加
export JAVA_HOME=/usr/local/java
export JRE_HOME=/usr/local/java/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
rm -rf /usr/bin/java
source /etc/profile
java -version # 验证java是否安装成功安装Elasticsearch
tar zxf elasticsearch-6.3.2.tar.gz
mv elasticsearch-6.3.2 /usr/local/es调整系统文件描述符的软硬限制
vim /etc/security/limits.conf
# 末尾添加
# 打开文件的软限制,ES要求系统文件描述符大于65535
* soft nofile 655360
# 打开文件的硬限制
* hard nofile 655360
# 用户可用进程数软限制
* soft nproc 2048
# 用户可用进程数硬限制
* hard nproc 4096
# JVM能够使用最大线程数
echo "vm.max_map_count=655360" >> /etc/sysctl.conf
sysctl -p配置Elasticsearch服务环境
useradd es
mkdir -p /es/{data,logs} # 日志及数据存放目录
chown -R es:es /usr/local/es /es # 使用es用户启动时,权限不对也会报错网络对时
ntpdate ntp.ntsc.ac.cn重启1.1主机
编辑elasticsearch.yml配置文件,ES默认就是集群模式的,所以只有一个节点也是集群模式
vim /usr/local/es/config/elasticsearch.yml
# 取消注释
cluster.name: my-application
node.name: node-1
# 添加
node.master: true
node.data: true
# 取消注释并修改
path.data: /es/data
path.logs: /es/logs
network.host: 192.168.1.1 # 改为本机ip
discovery.zen.minimum_master_nodes: 1 # master的最少节点数
# 取消注释
http.port: 9200192.168.1.4需要Kibana/Kafka/Zookeeper
安装Kibana
tar zxf kibana-6.3.2-linux-x86_64.tar.gz
mv kibana-6.3.2-linux-x86_64 /usr/local/kibana修改Kibana配置文件
vim /usr/local/kibana/config/kibana.yml
# 取消注释
server.port: 5601
server.host: "192.168.1.4"
# 用来连接es服务
elasticsearch.url: "http://192.168.1.1:9200"安装Zookeeper
tar zxf zookeeper-3.4.12.tar.gz
mv zookeeper-3.4.12 /usr/local/zookeeper
mkdir /usr/local/zookeeper/data
echo 1 > /usr/local/zookeeper/data/myid
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg编辑zookeeper配置文件
vim /usr/local/zookeeper/conf/zoo.cfg
# 修改
dataDir=/usr/local/zookeeper/data
# 添加
dataLogDir=/usr/local/zookeeper/data启动zookeeper服务
/usr/local/zookeeper/bin/zkServer.sh start安装Kafka
tar zxf kafka_2.12-2.1.0.tgz
mv kafka_2.12-2.1.0 /usr/local/kafka修改Kafka配置文件
vim /usr/local/kafka/config/server.properties
# 修改
broker.id=1 # 与zookeeper的myid一致
# 取消注释
listeners=PLAINTEXT://192.168.1.4:9092 # 改为本机ip
num.partitions=2 # 改为2,表示2个分区
zookeeper.connect=192.168.1.4:2181 # 改为本机ip,也是zookeeper所在ip启动kafka
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
netstat -anpt | grep 9092创建一个消息队列
/usr/local/kafka/bin/kafka-topics.sh --create \
--zookeeper 192.168.1.4:2181 \
--replication-factor 1 --partitions 2 --topic elk
# 创建elk模拟生产者发送消息验证kafka
/usr/local/kafka/bin/kafka-console-producer.sh \
--broker-list 192.168.1.4:9092 --topic elk
# 阻塞模式,可以输入内容
如:hello world再开一个终端,模拟消费者接受生产者的消息
/usr/local/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server 192.168.1.4:9092 --topic elk \
--from-beginning
# 同样为阻塞模式,接收消息
hello world192.168.1.5需要Logstash
安装Logstash
tar zxf logstash-6.3.2.tar.gz
mv logstash-6.3.2 /usr/local/logstash编辑logstash配置文件
vim /usr/local/logstash/config/logstash.yml
# 取消注释
path.config: /usr/local/logstash/config/*.conf # 配置文件路径
config.reload.automatic: true # 开启自动加载配置文件
config.reload.interval: 3s # 自动加载配置文件时间间隔
http.host: "192.168.1.5" # 改为本机ip192.168.1.6需要FileBeat/Nginx
安装filebeat
tar zxf filebeat-6.3.2-linux-x86_64.tar.gz
mv filebeat-6.3.2-linux-x86_64 /usr/local/filebeat安装Nginx
yum -y install pcre-devel openssl-devel zlib-devel gcc gcc-c++
tar zxf nginx-1.17.8.tar.gz -C /usr/src
cd /usr/src/nginx-1.17.8/
./configure --prefix=/usr/local/nginx
make && make install
ln -s /usr/local/nginx/sbin/nginx /usr/sbin/nginx启动nginx
nginxELK方案一
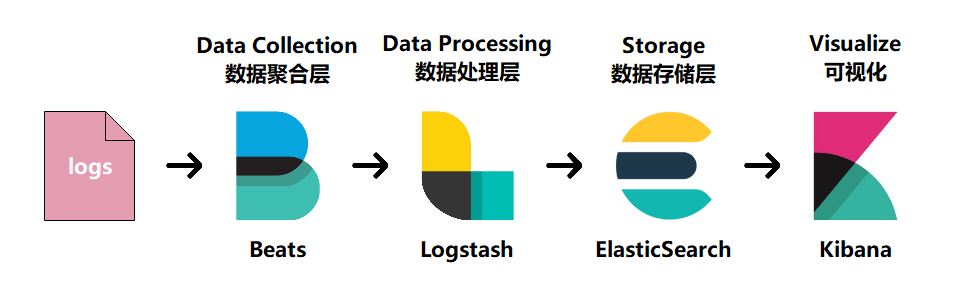
filebeat作为日志搜集器,搜集Web访问日志,缓解了Logstash在各服务器节点占用资源高的问题,beat所占系统cpu和内存几乎可以忽略不计,搜集到的日志发送给Logstash来处理,Logstash处理完日志后,会交给ES来存储,然后Kibana会将ES中分析后的数据形成可视化的界面。如:柱形图,条形图等等。此方案适合访问量较小的Web应用
整合环境
192.168.1.6
修改filebeat配置文件,将本机的nginx日志文件打标签为nginx,方便elasticsearch来创建索引
vim /usr/local/filebeat/filebeat.yml
# 添加注释
# filebeat.inputs:
#- type: log
# paths:
# - /var/log/*.log
# 添加以下内容为inputs配置
filebeat:
prospectors:
- type: log
paths:
- /usr/local/nginx/logs/access.log
tags: ["nginx"]
# 修改
enabled: true # 表示以上配置是否生效
# 添加注释
# output.elasticsearch:
# hosts: ["localhost:9200"]
# 取消注释
output.logstash:
hosts: ["192.168.1.5:5044"] # 该ip为logstash的主机ip192.168.1.5
新建nginx-logstash.conf文件,用来匹配日志索引
vim /usr/local/logstash/config/nginx-logstash.conf
添加:
input {
beats {
port => 5044 # filebeat端口号
}
}
output {
elasticsearch {
hosts => "192.168.1.1:9200" # 该ip为elasticsearch的ip和端口
index => "nginx" # 数据索引名
}
}192.168.1.1
启动es
su es
/usr/local/es/bin/elasticsearch192.168.1.6
启动filebeat
/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml192.168.1.5
启动logstash
/usr/local/logstash/bin/logstash -t /usr/local/logstash/config/nginx-logstash.conf 192.168.1.4
启动kibana
/usr/local/kibana/bin/kibana各个服务启动之后阻塞信息都是INFO就没问题,遇到WARN是no route的就关闭防火墙或者放行端口
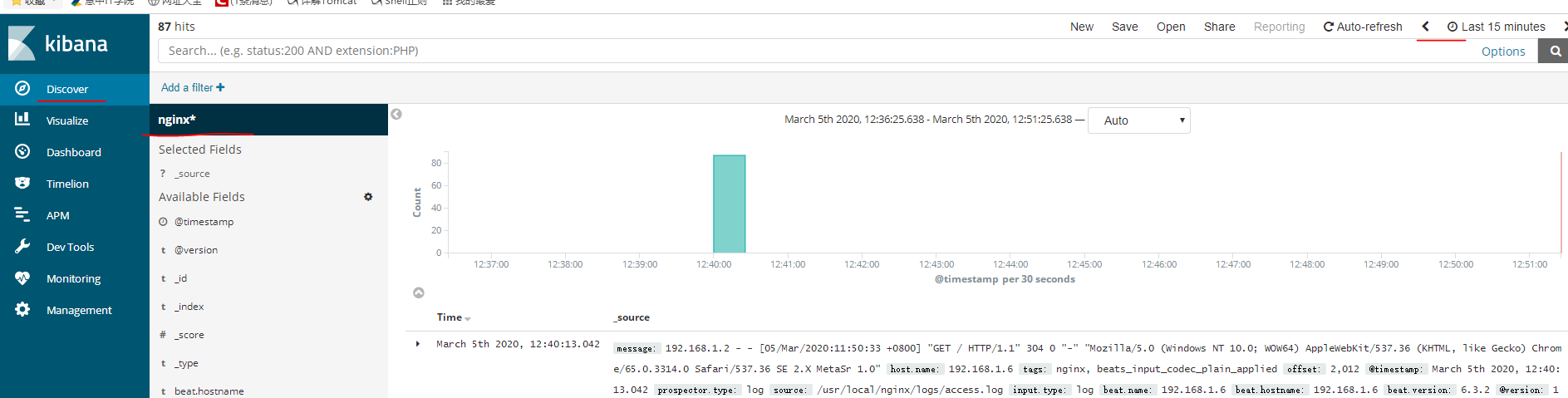
验证
现在访问nginx就会产生nginx日志,访问3分钟之内es阻塞会出现以下日志(因为数据传递比较慢)
[2020-03-05T12:40:14,969][INFO ][o.e.c.m.MetaDataCreateIndexService] [node-1] [nginx] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings []
[2020-03-05T12:40:15,348][INFO ][o.e.c.m.MetaDataMappingService] [node-1] [nginx/jaEyF28_QgWuV50Re8j4Ng] create_mapping [doc]
# 看到[nginx] creating index即成功在访问kibana的ip:5601,http://192.168.1.4:5601
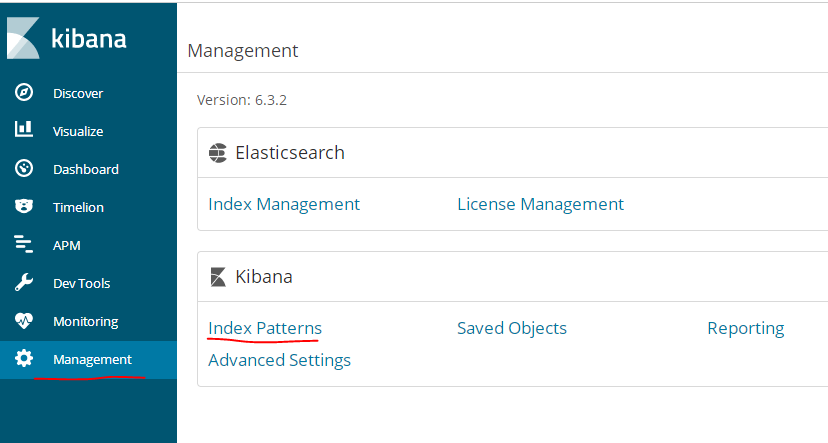
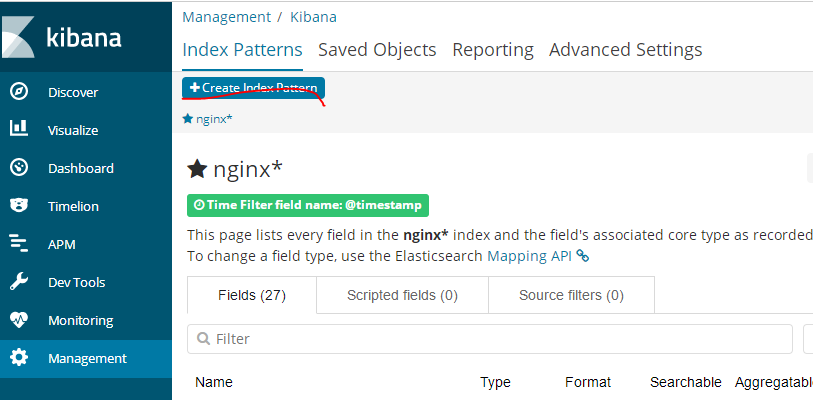
进入管理界面,通过设置索引样式可以匹配出具体索引的数据
如果es的阻塞日志没有成功的话,这里创建索引是不会success的,nginx*和logstash的nginx-logstash.conf中的output的index一致
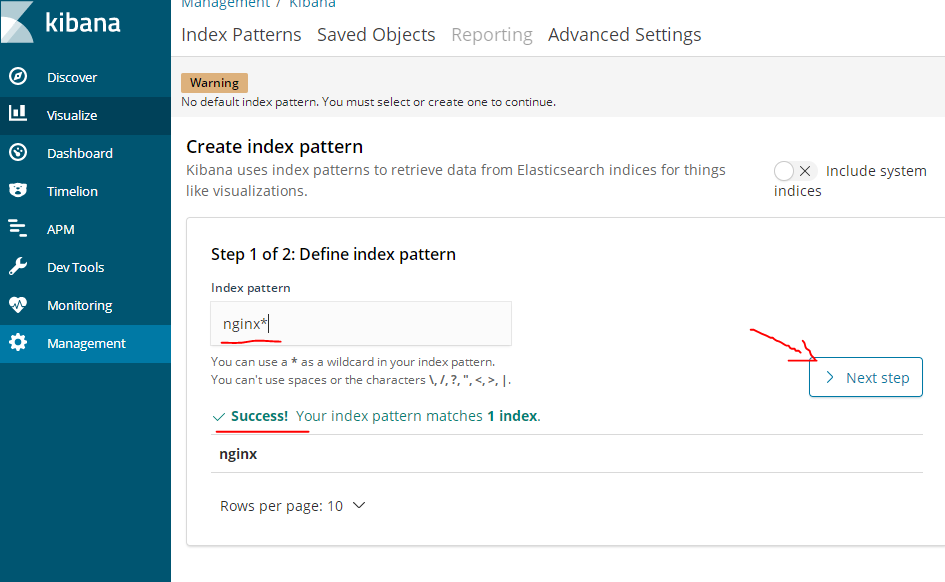
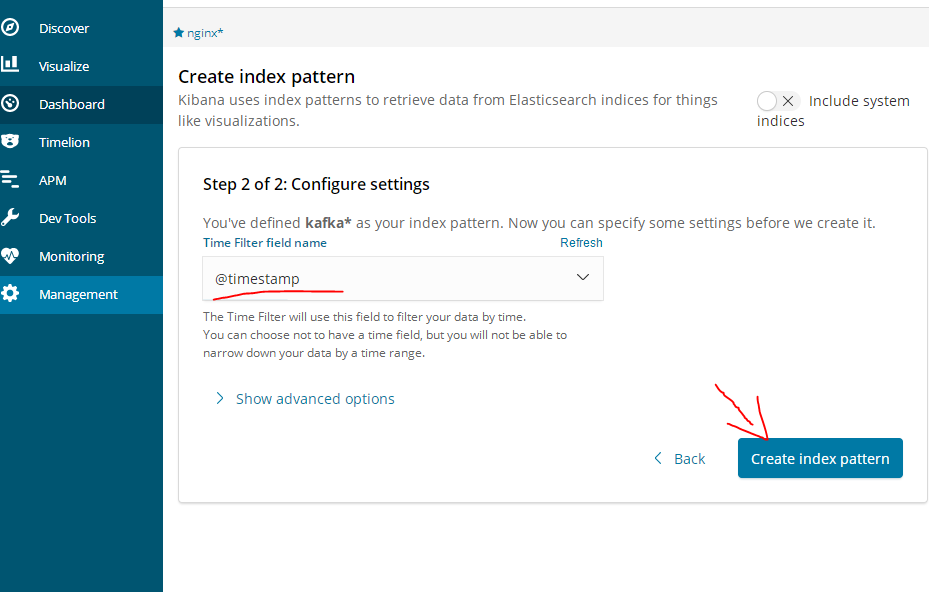
设置在这个索引里使用时间字段来进行过滤数据
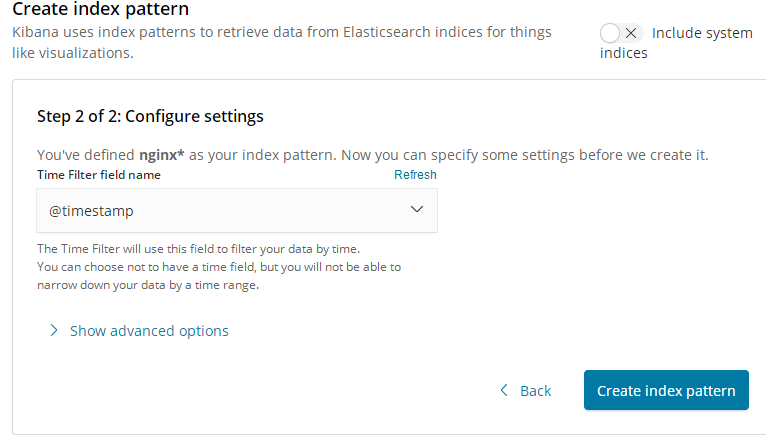
创建成功
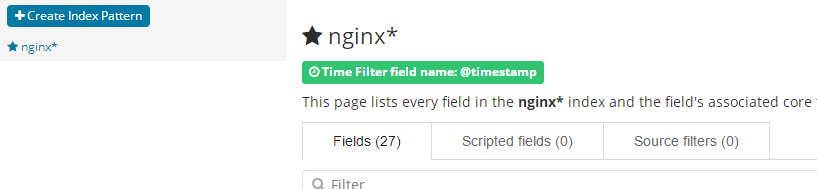
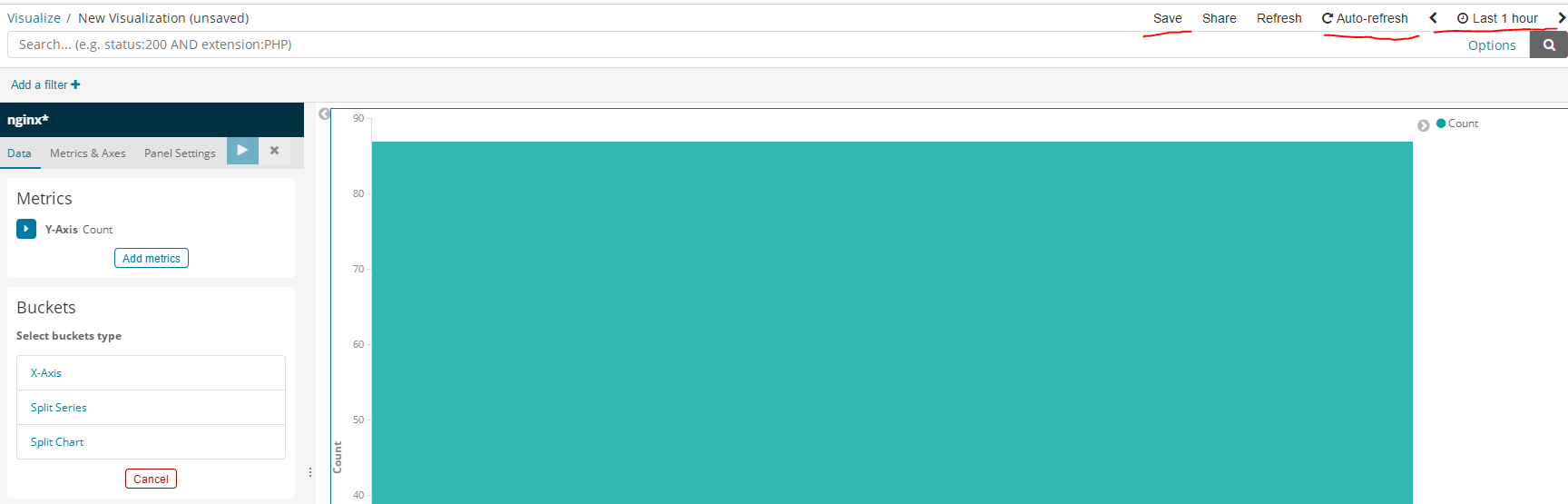
创建可视化图表
选择样式为条形图样式
选择为刚才创建的索引数据生成图表
右上方可保存图表,自动刷新间隔,时间维度
ELK方案二
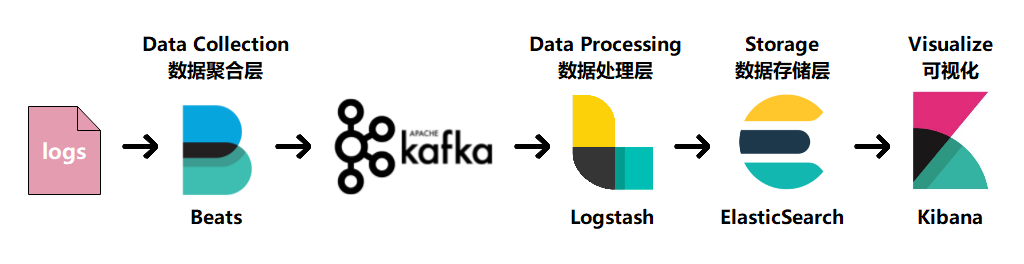
filebeat作为日志搜集器,搜集Web访问日志,缓解了Logstash在各服务器节点占用资源高的问题,beat所占系统cpu和内存几乎可以忽略不计,搜集到的日志发送给Logstash来处理,中间通过kafka消息队列来缓解当nginx被大量访问时,Logstash的处理日志的压力和ES存储数据的压力,Logstash处理完日志后,会交给ES来存储,然后Kibana会将ES中分析后的数据形成可视化的界面。如:柱形图,条形图等等。此方案适合访问量较大的Web应用
192.168.1.6
修改filebeat配置文件
vim /usr/local/filebeat/filebeat.yml
# 添加注释
#output.logstash:
# hosts: ["192.168.1.5:5044"]
# 添加
output.kafka:
hosts: ["192.168.1.4:9092"] # kafka所在ip
topic: "elk" # 已经添加过的elk192.168.1.5
修改logstash配置文件
vim /usr/local/logstash/config/nginx-logstash.conf
# 将input部分删了,重新编写为
input {
kafka {
bootstrap_servers => "192.168.1.4:9092" # kafka所在ip和端口
consumer_threads => 1 # 消费者线程数量
decorate_events => "true" # 将消息的偏移量等信息存储到日志
topics => "elk"
auto_offset_reset => "latest" # 自动存储偏移量
}
}
output {
elasticsearch {
hosts => "192.168.1.1:9200"
index => "kafka" # 与方案一区分
}
}192.168.1.1
启动es
su es
/usr/local/es/bin/elasticsearch192.168.1.6
启动filebeat
/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml192.168.1.5
启动logstash
/usr/local/logstash/bin/logstash -t /usr/local/logstash/config/nginx-logstash.conf 192.168.1.4
启动kafka
/usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties 启动kibana
/usr/local/kibana/bin/kibana验证
访问nginx使日志产生,ES生成kafka索引名的日志
http://192.168.1.6
然后访问kibana的ip及端口,验证kafka索引
http://192.168.1.4:5601
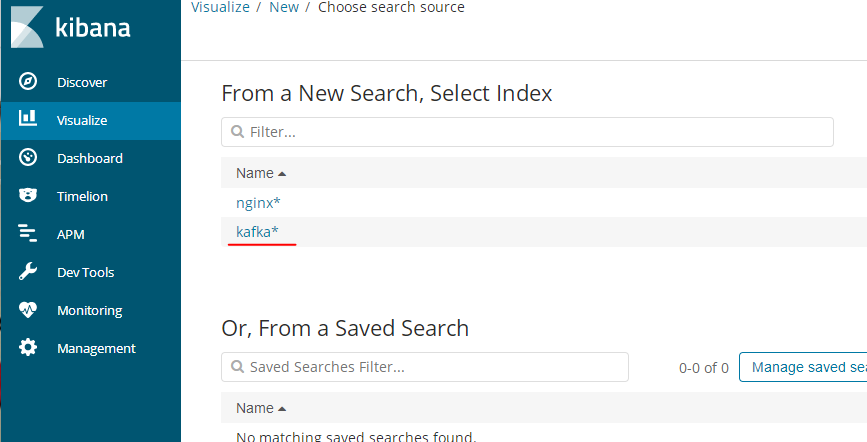
创建kafka索引
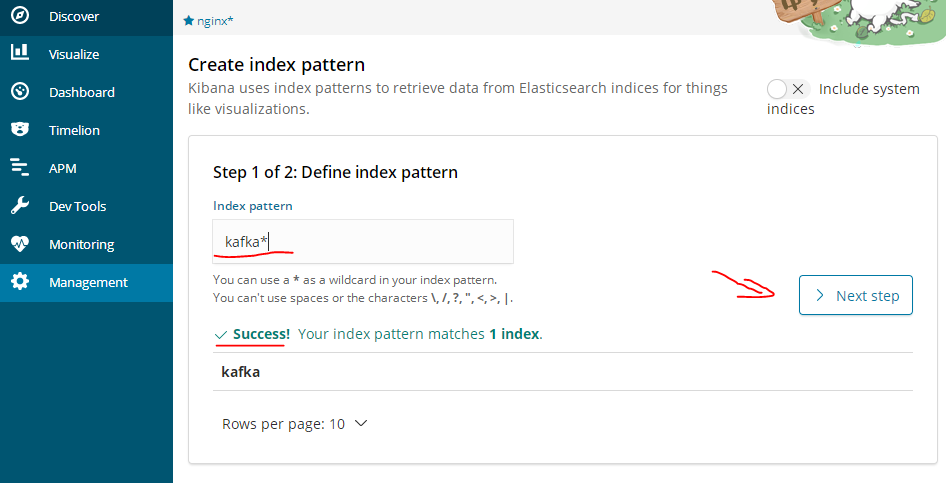
创建kafka索引的图表(nginx的访问次数情况)
因为我只访问了一次,所有count值为1

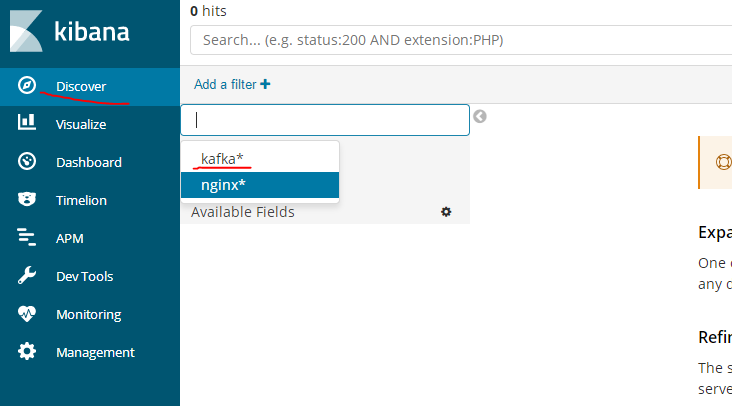
查看日志分析数据

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://www.feiyiblog.com/2020/03/06/ELK%E6%97%A5%E5%BF%97%E5%88%86%E6%9E%90%E7%B3%BB%E7%BB%9F/


