RabbitMQ消息队列


RabbitMQ消息队列介绍
AMQP协议:高级消息队列协议,是应用层开放的协议,为面向消息中间件设计, 基于此协议的客户端与消息中间件可以传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。RabbitMQ就是通过Erlang语言实现的一种消息中间件。
概念
RabbitMQ是一个遵循AMQP协议的消息中间件,它从生产者接受消息并传递给消费者,在这和过程中,根据路由规则进行路由、缓存和持久化。
消息队列中间件应用场景
1、异步处理: 在注册服务的时候,如果同步串行化的方式处理,让存储数据、邮件通知等挨着完成,延迟较大,采用消息队列,可以将邮件服务分离开来,将邮件任务之间放入消息队列中,之后返回,减少了延迟,提高了用户体验;
2、流量消峰(消除高峰):如淘宝购物节,先进先出原则。 秒杀活动中,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。 服务器在接收到用户请求后,首先写入消息队列。这时如果消息队列中消息数量超过最大数量,则直接拒绝用户请求或返回跳转到错误页面。秒杀业务根据秒杀规则读取消息队列中的请求信息,进行后续处理;
3、架构解耦: 电商里面,在订单与库存系统的中间添加一个消息队列服务器,在用户下单后,订单系统将数据先进行持久化处理,然后将消息写入消息队列,直接返回订单创建成功,然后库存系统使用拉/推的方式,获取订单信息再进行库存操作;
消息队列的种类
Redis 消息能够先进先出
MemCacheq 多条队列,并发性能比较好,完美兼容MemCache
MSMQ 只有发送和接收的功能,消息的最大载体只有4M
zeromq 号称最快的消息队列,高吞吐低延迟,在金融方面用的比较多
Kafka 日志收集,高吞吐,支持快速的持久化
activemq java的中坚力量,支持java语言比较好
RabbitMQ 最早的开源的消息队列,重量级的稳定消息队列,消息封装比较大,扩展性能较差,不能持久化
运维人员的消息队列架构
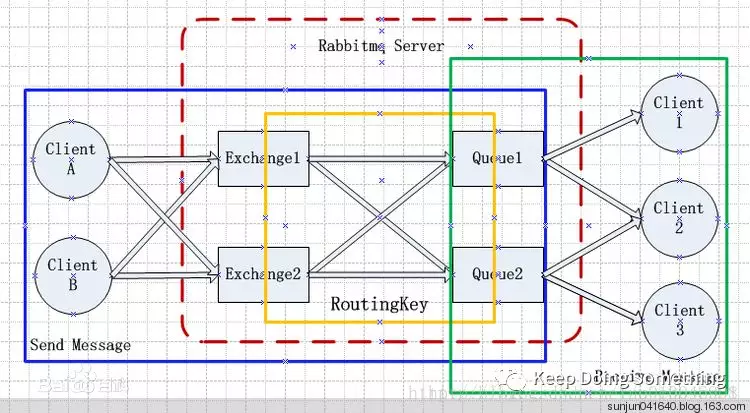
RabbitMQ server:消息队列服务,用于接收生产者产生的消息,并将消息分配给消费者
producer:生产者,生产消息,消息分为两部分,标签(用于匹配规则)和数据
consumer:消费者,用来消费队列分配的消息,处理完请求之后要给队列发送ack回应
ack回应:用来判断当前的消息是否被消费,如果被消费,消息将会被删除,如果没有,则重新回转等待被消费
RoutingKey:路由关键字 ,exchange根据这个关键字进行消息投递。
exchange:代表交换机,接收生产者的消息,根据自身的匹配规则,路由到哪个队列queue
connection:用来tcp连接producer、consumer和exchange
channel:虚拟通道, 消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
queue:队列(消息的载体)
上图的流程
ClientA或者B作为producer来发送消息,首先要与消息队列(RabbitMQ)服务器建立connection连接,获取一个channel会话,当到达消息队列(RabbitMQ)服务器,首先由exchange(交换机)来根据提前设定好的路由关键字(RoutingKey)或者其他的规则来分配消息进入哪个队列(queue),然后由consumer(消费者)获取queue的channel会话,开始监控队列中是否有它需要的数据消息,队列中如果有消息则取出消息,然后返回ack,queue会将队列中的该消息删除
官方过程
1、客户端连接到消息度列服务器,打开一个channel
2、客户端声明一个Exchange,并设置相关属性
3、客户端声明一个Queue,并设置相关属性
4、客户端使用Routing Key,在Exchange和Queue之间建立好绑定关系
5、客户端投递消息到Exchange
RabbitMQ集群
实验环境
三台服务器
RabbitMQ服务器1:192.168.1.1
RabbitMQ服务器2:192.168.1.4
RabbitMQ服务器3:192.168.1.6
实验目的
当使用图形化界面,创建了消息队列后,集群每台服务器中都会存在该消息队列,以防止单点故障引起的服务中断,实现高可用
实验步骤
安装RabbitMQ
借助erlang搭建RabbitMQ集群(拖入rpm包)
rpm -ivh erlang-18.1-1.el7.centos.x86_64.rpm解决RabbitMQ的依赖关系,并安装
yum -y install socat
rpm -ivh rabbitmq-server-3.6.15-1.el7.noarch.rpm 三台服务器都需要安装
三台服务器需要改主机名并重启机器,为了在使用RabbitMQ时,主机名的更改不会影响到服务的运行
hostnamectl set-hostname r1
hostnamectl set-hostname r2
hostnamectl set-hostname r3在本地hosts文件写入三台服务器的对应域名
vim /etc/hosts
192.168.1.1 r1
192.168.1.4 r2
192.168.1.6 r3将hosts文件使用scp传入其他两台服务器
重启之后启动RabbitMQ服务(三台全部都启动,注意防火墙要关闭)
[root@r1 ~]# systemctl start rabbitmq-server
[root@r1 ~]# rabbitmqctl cluster_status # 查看服务状态
Cluster status of node rabbit@r1
[{nodes,[{disc,[rabbit@r1]}]},
{running_nodes,[rabbit@r1]},
{cluster_name,<<"rabbit@r1">>},
{partitions,[]},
{alarms,[{rabbit@r1,[]}]}]RabbitMQ做集群就是将几台服务器的erlang的cookie值统一即可
查看随意一台服务器的erlang的cookie值,只有启动服务才会有cookie值
[root@r1 ~]# cat /var/lib/rabbitmq/.erlang.cookie
YLUJKXYAAKBBGDRZFXLJ
[root@r2 ~]# echo "YLUJKXYAAKBBGDRZFXLJ" > /var/lib/rabbitmq/.erlang.cookie
[root@r3 ~]# echo "YLUJKXYAAKBBGDRZFXLJ" > /var/lib/rabbitmq/.erlang.cookie
# 注意服务器的变化因为改变了后面两台的cookie值,所以需要重启服务器来生效
重启后两台服务器都需要重新启动rabbitmq-server服务
将r2添加到r1集群
[root@r2 ~]# systemctl start rabbitmq-server
[root@r2 ~]# rabbitmqctl stop_app # 停止集群服务
Stopping rabbit application on node rabbit@r2
[root@r2 ~]# rabbitmqctl join_cluster rabbit@r1 --ram # 将本机加入到rabbit@r1中
Clustering node rabbit@r2 with rabbit@r1
[root@r2 ~]# rabbitmqctl start_app # 启动集群服务
Starting node rabbit@r2
[root@r2 ~]# rabbitmqctl cluster_status # 查看状态,发现r2已经和r1在一起了
Cluster status of node rabbit@r2
[{nodes,[{disc,[rabbit@r1]},{ram,[rabbit@r2]}]},
{running_nodes,[rabbit@r1,rabbit@r2]},
{cluster_name,<<"rabbit@r1">>},
{partitions,[]},
{alarms,[{rabbit@r1,[]},{rabbit@r2,[]}]}]r3与r2操作一致
将r3添加到r1集群
[root@r3 ~]# systemctl start rabbitmq-server
[root@r3 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@r3
[root@r3 ~]# rabbitmqctl join_cluster rabbit@r1 --ram
Clustering node rabbit@r3 with rabbit@r1
[root@r3 ~]# rabbitmqctl start_app
Starting node rabbit@r3
[root@r3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@r3
[{nodes,[{disc,[rabbit@r1]},{ram,[rabbit@r3,rabbit@r2]}]},
{running_nodes,[rabbit@r2,rabbit@r1,rabbit@r3]},
{cluster_name,<<"rabbit@r1">>},
{partitions,[]},
{alarms,[{rabbit@r2,[]},{rabbit@r1,[]},{rabbit@r3,[]}]}]按装图形化界面的管理插件
[root@r1 ~]# rabbitmq-plugins enable rabbitmq_management图形化界面的用户
[root@r1 ~]# rabbitmqctl delete_user guest # 删除匿名用户
[root@r1 ~]# rabbitmqctl add_user test 123.com # 添加新用户并设置密码
[root@r1 ~]# rabbitmqctl set_user_tags test administrator
# 将新用户添加为管理员
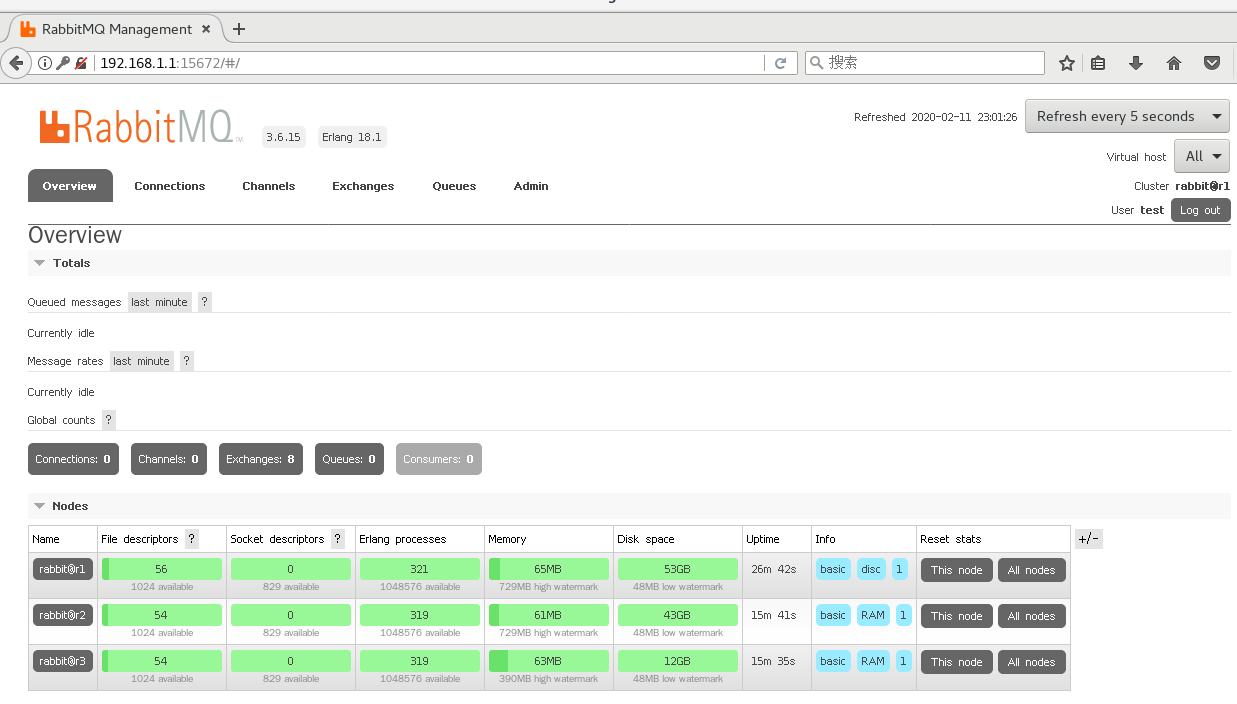
# 由于是集群,使用在这里添加的用户,其他集群服务器也可以使用此时使用图形化浏览器访问管理界面http://192.168.1.1:15672/
使用刚才创建的用户名密码来登录
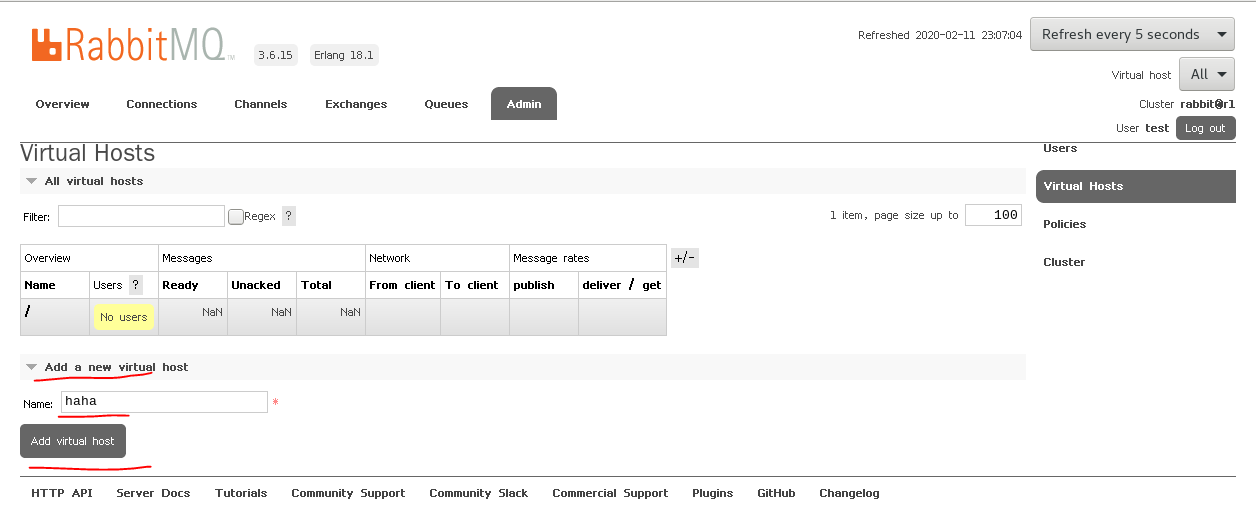
添加RabbitMQ的虚拟主机haha, 虚拟主机:一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。 因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机”/“。
设置虚拟主机管理用户
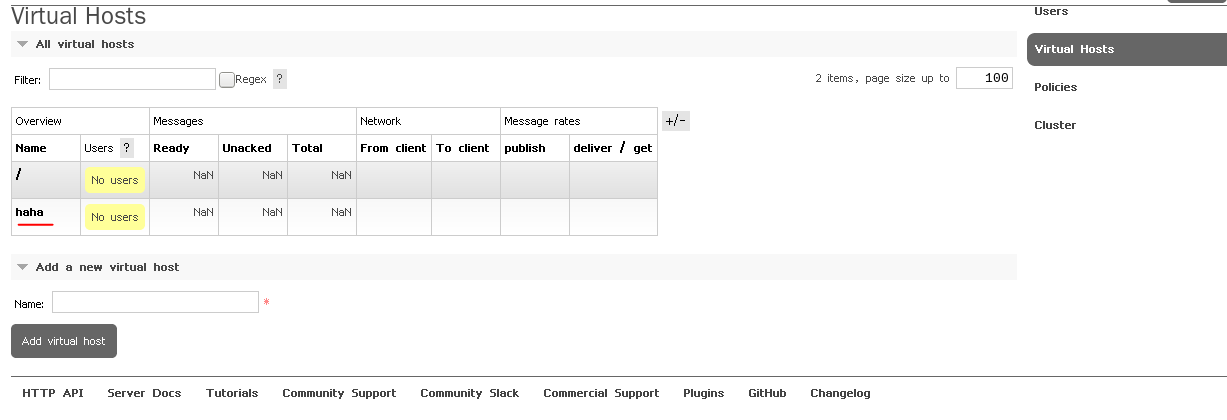
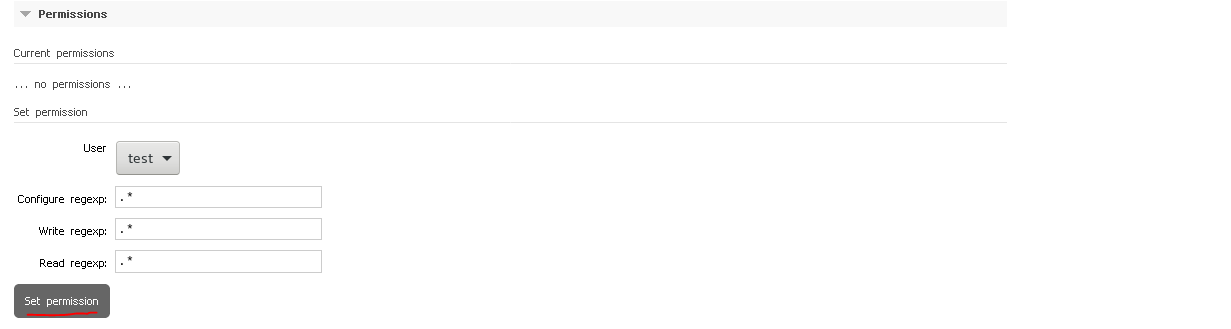
可以看到haha虚拟主机由test用户管理
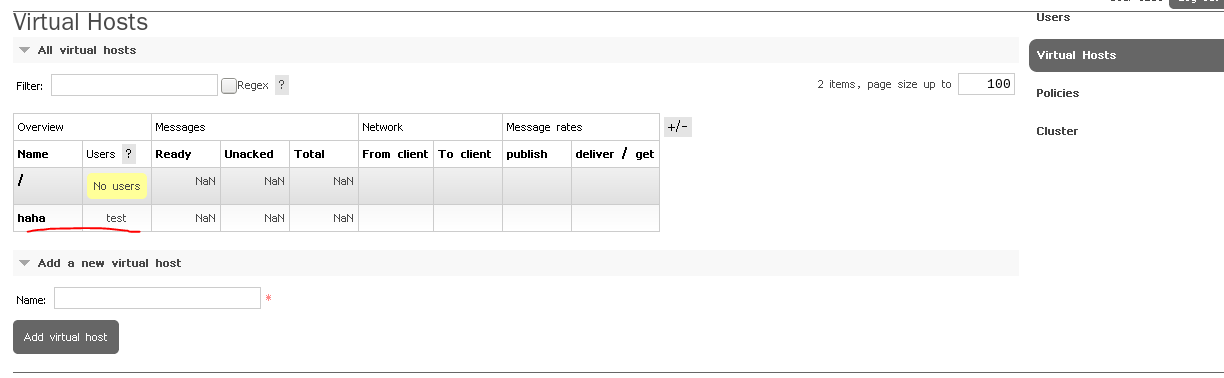
添加排列消息的策略
name:策略名
patter:匹配规则
apply to:直接绑定
priority:优先级
ha-mode:集群模式 all:给所有节点,所有节点都能看到发送消息后的队列
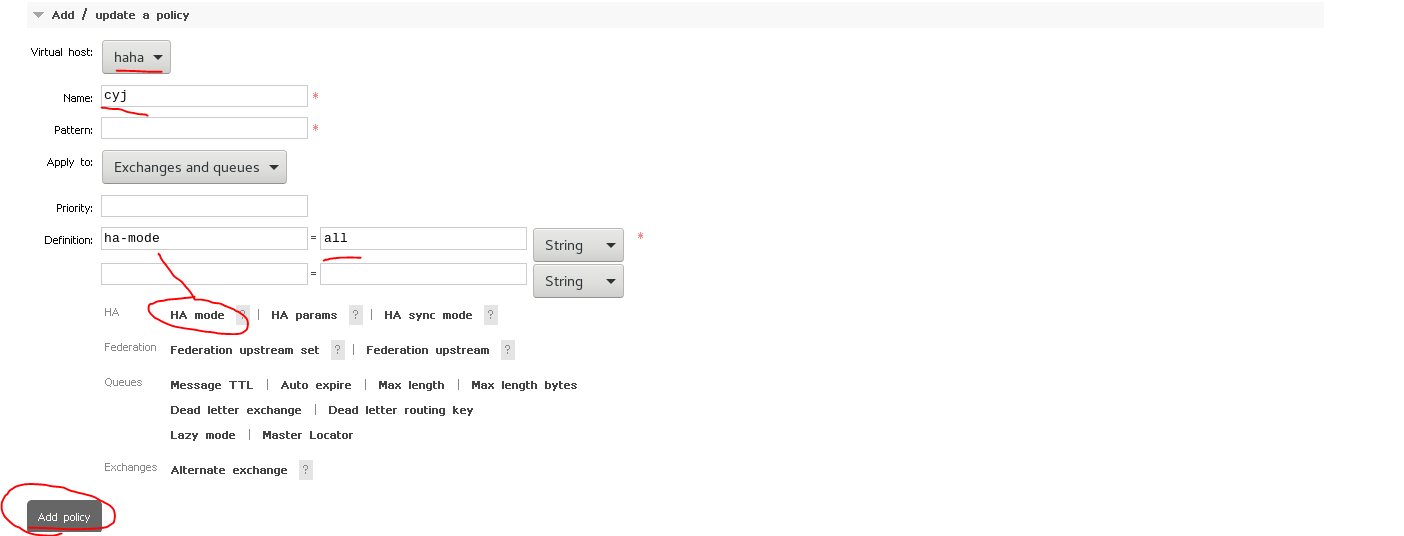
将策略和queue绑定
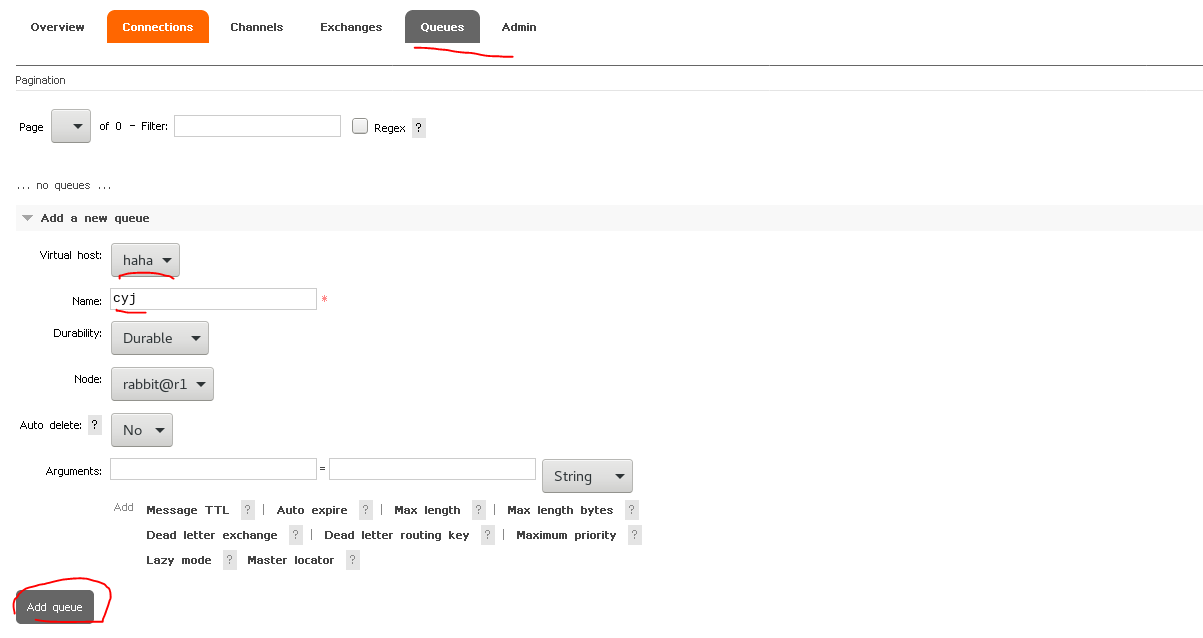
模拟发送消息
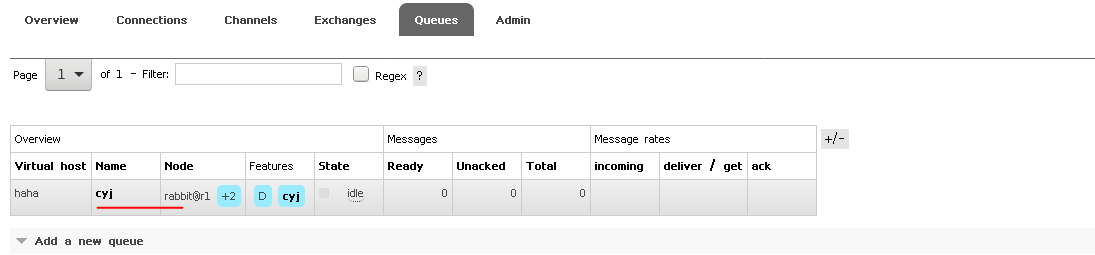
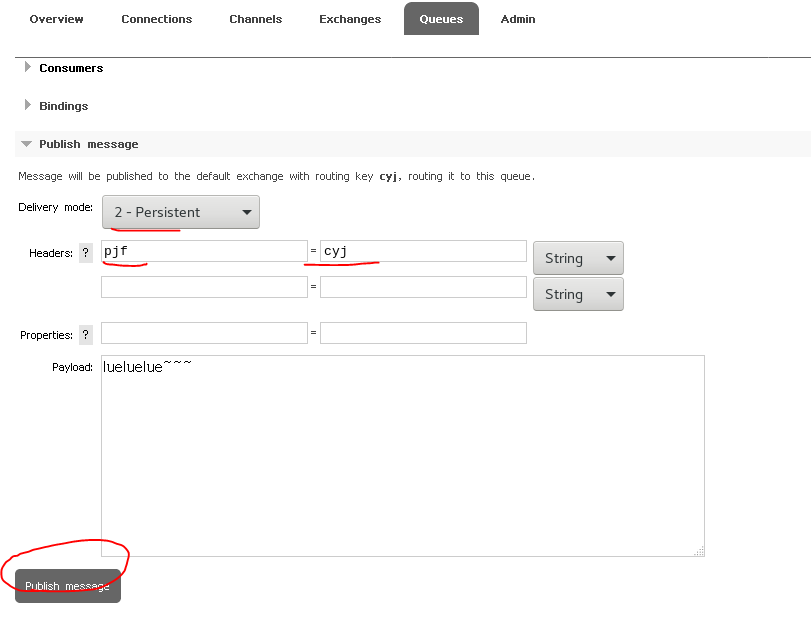
发送成功

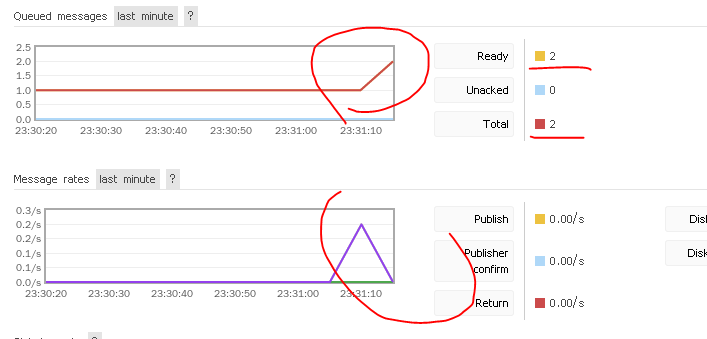
在集群中可以查看到队列
[root@r1 ~]# cd /var/lib/rabbitmq/mnesia/rabbit@r1/queues/
[root@r1 queues]# ls
2CYRBPMMEYQFEG4DF0YYP86V60博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://www.feiyiblog.com/2020/02/11/RabbitMQ%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/


